Automatiser ≠ gagner du temps : les erreurs qu’on voit tout le temps
Lisanne Bainbridge a décrit comme l’“ironie de l’automatisation” le fait que plus on automatise, plus le travail humain devient complexe.
Sur le papier, automatiser avec des outils comme Make, n8n ou Zapier semble évident : moins de tâches manuelles, moins d’erreurs, plus de vitesse. Dans la réalité, beaucoup d’équipes TPE/PME se retrouvent avec l’effet inverse : une stack d’automatisation difficile à maintenir, coûteuse, et parfois plus lente à faire évoluer qu’un simple script.
Le problème n’est pas l’automatisation. Le problème, c’est comment elle est utilisée.
Automatiser sans architecture, c’est déplacer le problème
Les outils no-code ont un avantage énorme : ils permettent de livrer vite. Une intégration Stripe → Notion → Slack peut être faite en quelques minutes.
Mais cette vitesse cache un coût : l’absence d’architecture.
Dans beaucoup d’équipes, l’automatisation commence par un besoin simple :
connecter deux outils, éviter une tâche répétitive, gagner du temps.
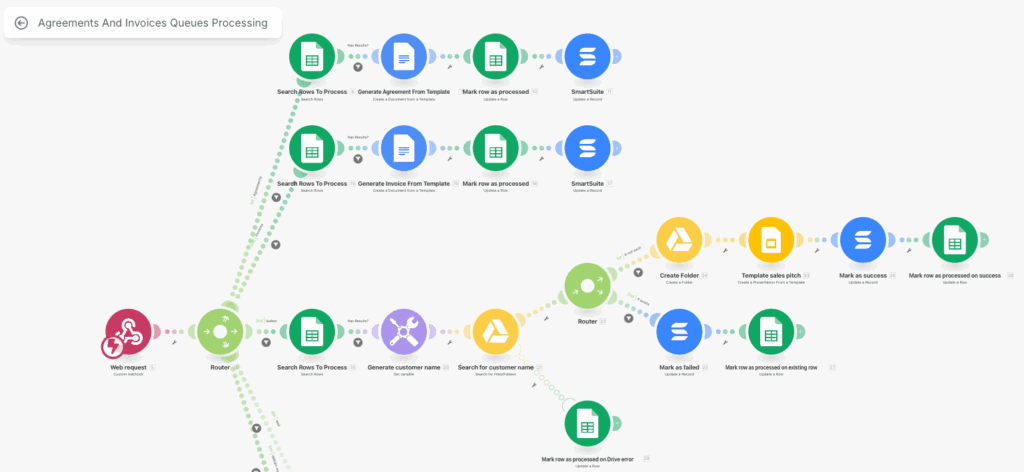
Puis les scénarios s’empilent. Un trigger appelle un autre scénario. Une logique métier commence à vivre dans Make. Une condition supplémentaire est ajoutée “juste pour gérer ce cas”.
Quelques semaines plus tard, ce qui était une automatisation devient un système.
Sauf que ce système n’a jamais été conçu comme tel.
L’erreur classique : transformer Make en backend
Un des patterns les plus fréquents consiste à utiliser Make comme une couche centrale de logique métier.
Au début, c’est logique. C’est rapide, visuel, accessible.
Mais progressivement :
- les règles métier s’accumulent dans les scénarios
- les dépendances entre automatisations augmentent
- les données transitent sans vraie normalisation
Résultat : Make devient un backend… sans les garanties d’un backend.
Ce phénomène est documenté dans la littérature sur la RPA (Robotic Process Automation), souvent définie comme une automatisation au niveau de l’interface plutôt qu’au niveau système. Cela la rend rapide à déployer, mais fragile face aux changements et difficile à maintenir à grande échelle.
Le problème n’est pas Make en soi. Le problème, c’est de lui faire porter un rôle pour lequel il n’est pas conçu.
Le piège du “ça marche donc on continue”
Un autre biais très courant est le suivant : tant que ça fonctionne, on continue.
Tu crées un premier scénario. Puis un deuxième. Puis un troisième qui dépend du premier.
À partir de là, sortir de l’outil devient coûteux.
C’est un cercle vicieux classique :
- plus tu construis dans l’outil
- plus tu deviens dépendant
- plus le coût de sortie augmente
- donc plus tu continues à construire dedans
Ce phénomène s’apparente à du vendor lock-in, mais à l’échelle de tes propres workflows.
Ce n’est pas un problème tant que le système reste simple. Mais dès qu’il devient critique, le risque explose.
Quand une automatisation devient plus complexe que le code
Un signal faible mais très révélateur : devoir “tricher” avec l’outil pour faire quelque chose de simple.
Par exemple :
- enchaîner plusieurs scénarios pour simuler une boucle
- multiplier les filtres pour reproduire une condition simple
- utiliser des webhooks internes pour gérer des états
Dans certains cas, on se retrouve avec des scénarios de dizaines de modules pour une logique qui tiendrait en quelques lignes de code.
Ce n’est pas un problème d’outil. C’est un problème d’adéquation.
Les outils no-code sont optimisés pour des workflows simples, linéaires, et peu variables. Dès que la logique devient conditionnelle, stateful ou complexe, le coût explose.
Le coût invisible : maintenance et debugging
Automatiser ne supprime pas le travail. Ça le déplace.
Au lieu d’exécuter une tâche, on doit :
- surveiller les scénarios
- comprendre pourquoi ça a cassé
- rejouer des exécutions
- gérer les erreurs silencieuses
Dans le monde logiciel, la maintenance représente entre 60 % et 80 % du coût total d’un système sur son cycle de vie.
Avec les outils d’automatisation, ce coût est souvent sous-estimé, car il n’est pas visible au départ.
Mais il apparaît rapidement :
- un champ change dans une API
- un outil modifie son format
- un scénario ne se déclenche plus
Et personne ne sait vraiment pourquoi.
Automatisation et dette technique
Chaque automatisation crée de la dette technique.
Pas forcément du code, mais de la logique distribuée :
- dans Make
- dans Zapier
- dans des webhooks
- dans des outils tiers
Le problème, c’est que cette dette est rarement documentée.
Contrairement à un repo Git, il n’y a pas toujours :
- de versioning clair
- de tests
- de review
- de documentation centralisée
Résultat : la compréhension du système devient implicite, souvent portée par une seule personne.
Et ça, à l’échelle d’une PME, c’est un risque majeur.
Comment automatiser sans se piéger
Automatiser efficacement, ce n’est pas éviter les outils no-code. C’est les utiliser au bon endroit.
Une règle simple fonctionne très bien en pratique :
garder la logique métier hors des outils d’automatisation.
Concrètement :
- les outils comme Make doivent orchestrer, pas décider
- la logique complexe doit vivre dans du code ou une API
- les données doivent être maîtrisées, pas simplement transférées
Autre point clé : accepter que tout ne doit pas être automatisé immédiatement.
Une automatisation instable ou mal conçue coûte souvent plus de temps qu’elle n’en fait gagner.
Enfin, il faut penser en termes de système dès le début :
- qui est responsable ?
- comment on debug ?
- que se passe-t-il si ça casse ?
Ces questions sont rarement posées au moment de créer un scénario. Elles deviennent critiques quelques semaines plus tard.
Conclusion
Automatiser ne fait pas gagner du temps par défaut.
Dans beaucoup de cas, cela déplace simplement le travail vers la gestion de la complexité, des erreurs et de la maintenance.
Les outils comme Make, n8n ou Zapier sont extrêmement puissants. Mais utilisés sans cadre, ils transforment des problèmes simples en systèmes difficiles à faire évoluer.
L’ironie de l’automatisation, décrite il y a plus de 40 ans, reste toujours d’actualité :
plus on automatise le simple, plus on doit gérer le complexe.
La vraie question n’est donc pas “peut-on automatiser ?”
Mais “doit-on automatiser, et à quel endroit du système ?”